
「Python 自動収益」と検索したあなたは、たぶんこう感じています。
Python 自動化で不労所得って本当に可能?副業で月5万くらいなら現実的?でも“稼げない”って声も多いし、スクレイピングは危ないとも聞く。まとめサイトみたいな情報は多いけど、結局どれが安全で再現性があるの?――そのモヤモヤ、すごく自然です。特に大学生や忙しい社会人ほど「時間は増やせないのに収入は増やしたい」ので、最短で確実な道を知りたくなりますよね。
この記事の結論はシンプルです。
Pythonで狙うべきは“完全放置の不労所得”ではなく、週1チェックで回る「手離れの良い仕組み」です。収益化は、①価値(誰の何分を減らすか)②課金導線(払いやすさ)③運用自動化(定期実行→処理→通知)の3点がそろって初めて安定します。ここを飛ばすと「作ったのに売れない」「運用が地獄で続かない」になりがちです。
私も最初は、作ることに集中して“売れる前提”で動いて失速しました。ところが、CSVを入れるだけでレポートが自動生成されるような小さな自動化を作り、先に販売導線を整え、失敗時の通知とログまで入れた瞬間、作業が減って回り始めました。スクレイピングのような地雷を踏まず、公式APIや公開データ中心に寄せたことで、止まりにくさも確保できました。
この記事では、Python 自動収益を安全に作る「型」と、月5万を現実的に積み上げる手順を、具体例つきで解説します。読後には、あなたが今日から何を作り、どう収益化し、どう週1運用に落とすかが分かります。遠回りせず、止まらず、積み上がる形へ進みましょう。
- Python 自動収益の現実的な定義と、再現性×リスク×手離れで判断する考え方
- 月5万を狙う最短ルートと、使える収益モデルの具体例
- 止まりにくい安全設計の作り方
Pythonで「自動収益」を作る全体像
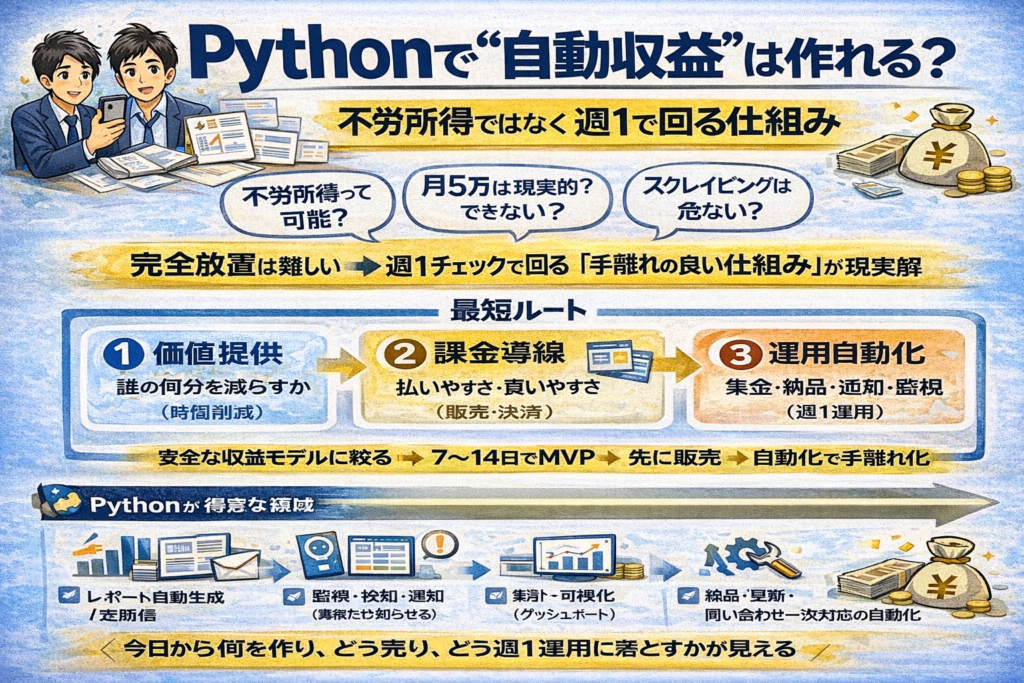
- 不労所得は可能?
- 副業で強い収益モデル
- 収益化の具体例
- 月5万を狙う“最短ルート”
- スクレイピングで稼ぐはアリ?
不労所得は可能?
Pythonで「まったく働かずに、ずっとお金が入る」不労所得を作るのは、現実にはかなり難しいです。
ただし、「最初にしっかり作って、あとは少ない手間で回る」手離れの良い仕組みなら作れます。ポイントは、Pythonを“お金を生む魔法”ではなく、“運用の手間を減らす道具”として使うことです。
「不労所得」ではなく「手離れの良い仕組み」として定義する
世の中では副業をする人が増えていますが、それは「働かなくていいから」ではなく、「生活や将来のために、もう少し収入がほしいから」という動きが大きいです。たとえば、総務省の就業構造基本調査の要約では、非農林業従事者のうち副業がある人は2022年に305万人で、5年前より60万人増えています。さらに「今の仕事を続けながら、他の仕事もしたい」と考える追加就業希望者は2022年に493万人で、5年前より93万人増えています。
また厚生労働省の資料では、副業をしている人を本業の所得階層で見ると、本業が299万円以下の層が全体の約7割を占めると示されています。
つまり現実の副業は、「完全に放っておいて増えるお金」よりも、「少しでも家計を良くするための働き方」に近いことが多いです。ここから、狙うべきは“不労”ではなく、“手離れ”だと分かります。
毎回手作業でやっていた集計や請求書作成をPythonで自動化して、同じ収入でも作業時間を減らす形が分かりやすいです。「収入が勝手に増える」より、「同じ収入を少ない時間で作る」に寄せると現実的になります。
収益が生まれる3要素:価値提供+課金導線+運用自動化
お金が入る仕組みは、ざっくり言うと「価値(役に立つもの)」「課金の道(支払いまでの道筋)」「運用の自動化(届ける・回す)」の3つがそろって初めて回りやすいです。
まず、オンラインで買い物をする人は増えています。経済産業省の市場調査では、2024年の日本国内BtoC-EC(消費者向け電子商取引)市場規模は26.1兆円に拡大しています。
さらに支払い面でも、経済産業省が算出した2024年のキャッシュレス決済比率は42.8%で、4割目標を達成しています。
つまり「ネットで売って、ネットで受け取る」土台は強くなっています。
ただし、土台があることと、あなたの商品が売れることは別です。価値が弱いと買われませんし、課金導線が分かりにくいと途中で離脱されます。ここでPythonが強いのは、購入後の配布、定期レポート送付、問い合わせ一次対応、在庫や価格の監視など「運用」を軽くする部分です。
データを集めて毎週レポートにして届けるサービスを考えると分かりやすいです。価値は「見たい数字がまとまっていること」、課金導線は「決済してもらえる場所」、運用自動化は「Pythonが収集・整形・配信を行うこと」です。このうち“自動化”だけでは売れず、価値と課金導線がそろって初めて回り始めます。
Pythonで自動化できる部分/できない部分
自動化できる作業は確かに多いです。OECDは、加盟国平均で「自動化リスクが高い職業」が約28%の雇用を占めると示しています。
これは「仕事が全部なくなる」という意味ではなく、「仕事の中の一部の作業は機械化されやすい」ことを示す数字です。Pythonはまさに、その“作業の部分”を置き換えるのが得意です。
一方で、営業や集客、信用づくりは自動化しにくい領域です。理由はシンプルで、人は「誰から買うか」「本当に大丈夫か」を気にするからです。さらに、集客を“自動化”と言いながら、規約違反スレスレの行為に寄せると危険です。たとえばGoogleは検索のスパム対策として、大量生成で順位操作を狙う行為(scaled content abuse)などをスパムポリシーで問題として扱っています。
また、収益化の入口が広告の場合、YouTubeでは「実ユーザーの関心に基づかない無効なトラフィック」を問題とし、広告収益を不正に増やす動きに注意を促しています。
Pythonで「見込み客リストを自動で集める」こと自体はできますが、相手が納得して買うまでの会話、信頼、実績の見せ方は結局人の仕事になりやすいです。ここを“自動化でゼロにする”と考えるほど、失敗かBAN(停止)に近づきます。
再現性×リスク×手離れの判断軸
「Python自動収益」を考えるときは、うまくいく確率(再現性)、失うものの大きさ(リスク)、放っておける度合い(手離れ)をセットで見た方が安全です。世の中のビジネスは入れ替わりも起きます。中小企業庁の白書では、(雇用保険事業年報を用いた指標として)開業率や廃業率が示され、直近の2018年度の開業率は4.4%、廃業率は3.5%という数字が紹介されています。
「作れば永遠に稼げる」は前提として置きにくいので、リスクを見ながら小さく試すのが現実的です。
下の表は、考え方の整理用のマトリクスです。
| 例 | 再現性 | リスク | 手離れ |
|---|---|---|---|
| 受注後に自動で納品できるデジタル商品(テンプレ、レポート等) | 比較的高い | 中 | 中〜高 |
| 企業向けの定期レポート配信(データ収集・整形・配信を自動化) | 中〜高 | 中 | 中 |
| 広告収益を狙った“自動量産”コンテンツ | 低〜中 | 高(評価低下・停止) | 高そうに見えて不安定 |
| 規約を無視した自動操作(クリック誘導、ボット等) | 低 | 非常に高(BAN・返金・法的問題) | 手離れ以前に継続困難 |
同じPythonでも「納品や配信を自動化する」は比較的安全に役立ちますが、「集客を機械で水増しする」方向に行くほど、止められたり、アカウントが使えなくなったりしやすいです。Amazonのアソシエイト・プログラムでも、ボットや自動ソフトウェアの利用など“悪用”にあたるケースでは紹介料を支払わない旨が明記されています。
うまい話の典型パターンと見抜き方
「誰でも簡単」「1日数分で月50万」など、うまい話ほど注意が必要です。消費者庁は2025年6月、簡単な副業をうたい高額なサポートプランを契約させる事業者について注意喚起を出しており、「このプランなら月50万が当たり前」「返金保証がある」などの勧誘で、報酬が得られなかったという相談が消費生活センター等に多数寄せられているとしています。
また消費者庁は2022年にも、「誰でも1日当たり数万円を稼ぐことができる」などの勧誘でマニュアル購入に誘導するケースを公表しています。
BANや規約違反のリスクも現実にあります。たとえばGoogle AdSenseは、無効なトラフィックやポリシー違反がアカウントの停止・閉鎖につながること、無効な行為を誘発する設置や操作が禁止であることを示しています。
YouTubeも無効なトラフィックの例を挙げ、実ユーザーの関心に基づかない人工的な動きを問題としています。
「自動でクリックして広告収益」「自動でフォローして集客」「自動で大量投稿して検索上位」などは、短期では数字が動いて見えても、規約や品質評価の壁で止まりやすいです。安全側に倒すなら、Pythonは“だますための自動化”ではなく、“役に立つ提供を安定させる自動化”に使うのが王道です。
まとめ
Pythonで不労所得を作る発想は魅力的ですが、現実的には「手離れの良い仕組み」を目標にした方がうまくいきます。副業は増えている一方で、多くの人は生活のために働き方を工夫しているのが実態です。
収益化は「価値」「課金導線」「運用自動化」がそろって初めて回り、Pythonはとくに運用の手間を減らすところで力を発揮します。集客や信用づくりまで全部自動にしようとすると、失敗や規約違反のリスクが一気に上がります。
うまい話ほど、消費者庁の注意喚起のような事例に似ていないかを確認して、再現性・リスク・手離れのバランスで小さく試すのが安全です。
副業で強い収益モデル
Pythonで「自動収益」を狙うなら、強いのは“人の手を減らしても価値が落ちにくい”モデルです。とくに、B2Bの小さなSaaS(定期課金)、データを集めて配るレポート(定期発行)、完成品のテンプレやツール販売(販売)、そしてAPIの従量課金(手数料に近い)が現実的です。
一方、ブログやYouTubeなどの広告モデルは市場が大きい反面、成果が出るまで時間がかかりやすく、完全自動にはなりません。Pythonは「売上を勝手に生む魔法」ではなく、「運用の手間を小さくして利益を残しやすくする道具」として使うのが近道です。
マイクロSaaS/定期課金
マイクロSaaSは「小さな困りごとを、毎月の料金で解決するサービス」です。B2Bと相性が良い理由は、会社は“毎月の業務”が多く、便利だと継続しやすいからです。
土台になるデータとして、日本のBtoB-EC(企業間の電子商取引)は2024年に514.4兆円、EC化率は43.1%まで伸びています。会社同士の取引がオンラインに移っているので、「ネットで申し込み、継続課金で使う」流れが作りやすいです。
さらに、企業のクラウド活用が広がっていることも追い風です。企業のクラウド利用率が2024年に80.6%まで増えた、という整理もあります。
Pythonが効くのは、日次・週次の自動処理、データ取り込み、通知、請求やアカウント管理の“運用部分”です。ここが自動になるほど、少人数でも続けやすくなります。ただしB2Bは「信頼」「サポート」「障害対応」が必要なので、完全放置ではなく“少ない手間で回る”を目標にすると失敗しにくいです。
データ・レポート販売
データ・レポート販売は、「集めにくい情報を集めて、わかりやすくして届ける」仕事です。毎月や毎週の定期レポートにすると、サブスクにも寄せられます。
材料(データ)があることは強みです。たとえば、政府が保有する法人情報をまとめて提供する仕組みがあり、APIでも取得できます。
また、BtoCのネット市場も2024年に26.1兆円まで拡大しており、オンラインで買う行動そのものが当たり前になっています。
Pythonで自動化しやすいのは、データ収集、整形、グラフ化、PDFやスプレッドシート出力、配信(メール送信や会員ページ更新)です。レポートの「毎回同じ作業」を機械に任せられるので、価値の中心である“見方の工夫”や“結論の説明”に時間を使えます。注意点は、元データの仕様変更や欠損が起きることです。止まったときに直せるよう、監視とログだけは仕組みに入れておくと安全です。
テンプレ・スクリプト・自動化ツール販売
テンプレやスクリプト販売は、「1回作って、何度も売る」販売モデルです。購入後のサポートを最小限にしやすく、手離れが良くなりやすいのが強みです。
オンラインで“モノやサービスを買う市場”が大きいこと自体が根拠になります。2024年のBtoC-ECは26.1兆円まで増えています。
ここに、業務効率化のニーズを乗せると売りやすくなります。たとえば「請求書作成」「データの自動集計」「在庫チェック」「定期バックアップ」など、やることが決まっている作業はテンプレ化と相性が良いです。
Pythonでできる工夫は、インストールを簡単にする、設定画面を用意する、エラー時のメッセージをわかりやすくする、といった“使いやすさ”です。完成品の価値は「動くこと」だけでなく「迷わず使えること」にあるので、説明書やサンプルデータを同梱して、質問が来にくい形にすると収益が安定しやすいです。
API提供
API提供は、「あなたの機能を他人のサービスから呼び出せる形にして、回数に応じて課金する」モデルです。うまくいくと“利用が増えるほど売上が増える”ので、手数料型に近い動きになります。
社会全体でAPI連携が重視されていることは、追い風の根拠になります。たとえば経済産業省では、クレジットカード分野のAPI連携推進について検討会資料が公開されています。
また、キャッシュレス決済比率は2024年に42.8%(決済額141.0兆円)まで伸びています。決済や会計まわりはAPI連携の需要が生まれやすい領域です。
PythonでAPIを作るときは、認証(鍵の管理)、利用制限、課金計測、ログ、障害対応が重要です。ここを軽く見ると、悪用やコスト増で赤字になりやすいので、最初は小さな機能で始めて、使われ方を見ながら強化していくのが現実的です。
コンテンツ×自動化の現実ライン
広告モデルは「見られるほど収益が増える」ので夢があります。ただ、競争が強く、成果が出るまで時間がかかりやすいのが現実です。
市場が大きい根拠はあります。2024年の日本のインターネット広告費は3兆6,517億円で過去最高を更新しています。
つまりお金は動いていますが、そのぶん“取り合い”も起きます。
Pythonが役に立つのは、ネタ管理、リサーチの整理、予約投稿、反応の集計、メール配信の整形など「裏方の自動化」です。けれど、読者が「読みたい」「見たい」と思う内容づくりは人の仕事になりやすいです。だから現実ラインとしては、コンテンツ単体で一気に稼ぐより、コンテンツで集客して、サブスクや販売(ツールやレポート)に流す形のほうが安定しやすいです。
まとめ
Python副業で“強い収益モデル”を作るコツは、定期課金・販売・従量課金のように、仕組み化しやすい型を選び、運用の手間をPythonで削ることです。B2B-ECやクラウド利用が広がっているので、マイクロSaaSや定期レポートは現実的な選択肢になります。
テンプレや自動化ツール販売は、完成品の価値を作れれば手離れが良くなります。API提供は伸びると強い一方、セキュリティや課金管理など“守りの設計”が必須です。広告モデルは市場規模が大きいですが、伸びるまで時間がかかりやすいので、サブスクや販売に繋げるルートとして使うのが堅実です。
収益化の具体例
Pythonで「自動収益」を作るコツは、たくさん頑張って売ることよりも、「同じ作業を毎回やらなくていい形」に変えることです。
つまり、毎週・毎日くり返す作業をPythonに任せて、届けるところまで仕組みにすると、お金が入りやすくなります。
その具体例として、定期レポート、監視と通知のSaaS、データの見える化、業務自動化パッケージが現実的です。さらに「小さな自動化」から商品に育てる考え方も大切になります。
定期レポート自動生成
「レポート作り」は、会社でも個人でも“毎回同じ流れ”になりやすいので、自動化と相性がとても良いです。
実際、IPAのDX動向調査では、DXの成果が出ている企業ほどデータの利活用が進んでいます。たとえば「成果が出ている」企業では「全社で利活用している」が26.3%なのに対し、「成果が出ていない」企業では8.1%にとどまっています。部署ごとの利活用でも、46.8%と29.7%で差があります。つまり、データをまとめて使える会社ほど、成果につながりやすい傾向があると言えます。
ここでのポイントは、レポートそのものより「毎回の面倒」を減らすことです。CSVを集めて、合計や平均との差を出し、見やすい形(PDFやスライド)にして、決まった日に自動で渡せるようにすると「手離れの良い商品」になりやすいです。
たとえば「毎週の売上・広告費・利益を1枚で見たい」お店や小さな会社は多いです。最初に形を作り、あとはCSVを置くだけでレポートが出るようにすると、月額の定期契約(サブスク)にもつなげやすくなります。
| 入力 | Pythonの仕事 | 出力 | お金のもらい方 |
|---|---|---|---|
| CSV(売上、広告、在庫など) | 集計、グラフ化、文章の自動生成 | PDF/スライド | 月額、または1回ごとの作成料 |
監視・検知・通知SaaS
監視SaaSが強い理由は、「トラブルはゼロにできないけど、早く気づけば被害が小さくなる」からです。
IPAの中小企業向け調査の速報では、サイバーインシデントが起きた企業の被害額は平均73万円、復旧までの期間は平均5.8日という数字が示されています。これは「気づくのが遅れるほど、時間もお金も失いやすい」ことをイメージしやすいデータです。
Pythonでできるのは、決まった間隔で「見に行く」ことです。たとえば、ページが落ちていないか、商品価格が変わっていないか、エラーが増えていないか、更新が止まっていないかを自動で確認して、異常があれば通知します。
通知はメールでもチャットでも良いですが、ここで価値になるのは「すぐ分かる」「誰が見ても同じ判断になる」ことです。
たとえばEC運営者向けに「競合価格の変化を見張って、動いたら通知する」仕組みを作り、監視対象の件数に応じて月額料金にする形は作りやすいです。大事なのは、規約や利用条件を守って、過剰アクセスにならない設計にすることです(ここを雑にすると、止められる原因になります)。
情報の整理・可視化
「データが散らばっていて判断できない」は、よくある困りごとです。ここが解決できると、価値が長持ちします。
経済産業省のDXレポート2.2では、顧客行動をデータでどれだけ可視化できているかが差別化要因になり得ること、また組織や業務を横断して広くデータが共有され活用できていることが重要だと整理されています。
一方で、現実には「データ活用で全社的に十分な成果が出ている」と答えた組織は8%という調査結果もあります。つまり、ちゃんと見える化できている会社はまだ少なく、ニーズが残っていると言えます。
ここでの収益化は、初期費用(作る作業)+月額(保守・更新)にしやすいです。理由は、データの形が変わったり、見たい指標が増えたりするからです。
たとえば「売上は見えるけど、広告費と利益がつながっていない」会社に対して、毎日自動更新されるダッシュボードを作ると、手放しで使い続けてもらいやすくなります。
業務自動化パッケージ
業務自動化パッケージが強いのは、どの会社にも「毎日やる面倒」があるからです。しかも今後、人手は増えにくいです。
国立社会保障・人口問題研究所の将来推計人口では、15〜64歳人口(働く中心の年代)の割合が2020年の59.5%から下がり続け、2070年には52.1%になる推計が示されています。さらに、15〜64歳人口は2020年の7,509万人から減っていき、2070年には4,535万人まで減少するとされています。
また日本銀行の資料でも、人手不足感が幅広い業種・規模に広がっていることが示されています。
こうした状況では、「人を増やす」より「作業を減らす」ほうが現実的になりやすいので、自動化の価値が上がります。
たとえば、請求書作成、入金チェック、定型メール送信、在庫一覧の更新、日報のまとめなどは、やることが決まっているのでパッケージ化しやすいです。売り方としては、買い切り(完成品の販売)にして、追加対応は別料金にすると、手離れが良くなります。
「小さな自動化」から商品化に繋がるネタの見つけ方
商品になるネタは、いきなり大きいアイデアから出ることもありますが、多くは「小さな面倒」から育ちます。
経済産業省は、2023年版の中小企業白書・小規模企業白書のポイントとして、ビジョン・目標の設定や業務の棚卸しを戦略的に実施している企業ほどデジタル化が進展していること、必ずしも高度なデジタル人材がいなくても進められることを示しています。
つまり、難しいAIや巨大サービスを作る前に、「何に時間が取られているか」を言葉にして整理し、そこから小さく作るのが近道です。
ネタ探しの現実的な方法は、「1日に何回も出てくる作業」「ミスが起きやすい作業」「やり方が毎回ほぼ同じ作業」を、まず1つだけ選ぶことです。小さく作って、使った人に「どこが一番助かったか」を聞き、同じ悩みを持つ人が他にもいるかを確かめると、商品としての形が見えてきます。
下の表のように、最初は“強い条件”がそろっているものから始めると失敗しにくいです。
| チェック項目 | 目安 |
|---|---|
| くり返し回数 | 毎日〜毎週、必ず発生する |
| 作業の決まり具合 | 手順がほぼ固定されている |
| ミスの起きやすさ | コピペや転記が多い |
| 自動化後の価値 | 時間が減る、ミスが減る、判断が早くなる |
まとめ
Pythonの自動収益は、「自動で回る価値」を作れたときに現実味が出ます。定期レポートは“同じ流れ”を自動化しやすく、監視と通知は“早く気づく価値”があるのでサブスクに向きます。ダッシュボードは“見える化”のニーズが強く、業務自動化パッケージは人手不足の流れの中で価値が上がりやすいです。
そして一番堅いのは、身近な小さな自動化を作って、役立つ形に整え、同じ悩みの人へ届けていくことです。最初から大きく作るより、小さく始めて、仕組みを育てるほうが続きやすくなります。
月5万を狙う“最短ルート”
Pythonで月5万円を最短で狙うなら、「大きいサービスを作る」より、「小さな自動化を商品にして、売れる形に育てる」ほうが近道です。
流れは、収益モデルを安全に絞り、誰の何分を節約するかを決め、7〜14日で最小の完成形を作り、先に課金を通し、最後に集金・監視・サポートを自動化して手離れ化します。
月5万円は、月1万円の人が5人でも届きます。大事なのは、すごい機能より「役に立つ」「買える」「続けられる」の3つです。
ステップ0:収益モデルを“安全に”絞る
最初に「安全」を外すと、途中でゼロに戻りやすいからです。たとえば消費者庁は、「簡単に稼げる」などをうたい高額契約へ誘導する副業の注意喚起を出しています。こういう話に近い形に寄ると、返金トラブルや信用低下が起きやすく、積み上げが消えやすいです。広告収益でも、無効なトラフィックなどでアカウントが止まると、収益の道が急に閉じることがあります。だから最短ルートほど、「止まりにくい道」を選ぶのが結果的に早いです。
最初は「時短ツールの販売」「定期レポート作成」「監視と通知(小さなSaaS)」のように、価値が分かりやすく、ルールに触れにくいモデルにします。たとえば「毎週の売上CSVを入れると1枚レポートが出る」を商品にすると、やることが明確で、再現もしやすいです。
ステップ1:「誰の何分を節約するか」を決める
人手が増えにくい時代ほど「ムダ時間を減らす」価値が上がるからです。労働力不足の見通しが語られている資料もあり、会社側は「人を増やす」より「作業を減らす」ほうに動きやすくなります。だから「誰の何分を減らすか」をはっきり言える商品は、買う理由が強くなります。
「ネットショップ運営者の、毎日の売上チェックと在庫チェックの合計20分を減らす」のように、対象と時間を固定します。20分が毎日なら、月で約10時間ぶんです。相手が“月10時間ラクになる”なら、月5,000円〜1万円の価値を感じる人が出やすくなります。
月5万円は次のように逆算できます。
| 形 | 月5万円までのイメージ |
|---|---|
| 月1万円のサブスク | 5人(5社)で達成 |
| 月5,000円のサブスク | 10人(10社)で達成 |
| 1本2万円のレポート | 月3本で達成(少し余る) |
| 4,980円のツール販売 | 月11本で達成(少し余る) |
ステップ2:7〜14日粒度でMVPを作る
作り込みすぎると「欲しがられていなかった」ときの損が大きいからです。失敗理由の分析では、「市場が必要としていない」が大きな原因としてよく挙げられます。だから最短ルートは、まず小さく作って、必要かどうかを早く確かめる動きになります。
7〜14日で作る最小の完成形(MVP)は「入力が簡単」「出力が分かりやすい」「1回でも役に立つ」の3つだけに絞ります。たとえば「CSVを置く→自動で集計→PDF1枚が出る」だけで十分です。最初は指標を3つまで、グラフも1つまでにして、まず“動く完成品”を出します。
ステップ3:課金・販売を先に通す
「作る前に売る」に近い順番のほうが、ムダな開発を減らせるからです。今はネットで買う土台が大きく、BtoC-ECやBtoB-ECの市場規模が拡大しています。支払いもキャッシュレスが増えていて、「説明して、すぐ払ってもらう」流れを作りやすい環境です。だから、先に販売の道を作っておくと、月5万円への距離が短くなります。
まず説明ページ(LP)を1枚作り、「無料で1回だけレポート作成」や「無料で7日だけ監視」を用意します。無料で“助かった”が出た人に、有料へ移ってもらいます。月1万円×5人(5社)を目標にすると、最初の設計がブレにくいです。
ステップ4:運用自動化で手離れ化
月5万円を「毎月」続けるには、売るより“回す”が重要になるからです。小さな事業ほど、日々の雑務に時間を取られると続きません。中小企業の事例でも、在庫管理などを工夫して探す時間をゼロにしたり、作業を大きく短縮したりして成果が出た話があります。あなたの副業も同じで、手作業を減らすほど、同じ売上でもラクになります。
集金は自動、納品も自動、監視も自動、よくある質問への一次対応もできるだけ自動にします。レポートなら「受け取りフォルダにCSVが入ったら自動生成して送る」、監視SaaSなら「異常だけ通知して、正常は静かにする」、ツール販売なら「設定画面とエラー説明を丁寧にして質問が来にくい形」にします。こうすると、少ない時間で回りやすくなり、月5万円が“積み上がる形”になります。
まとめ
Python副業で月5万円を最短で狙うなら、「小さく作る→検証→改善」を回しやすい形にするのがコツです。
最初に安全な収益モデルへ絞り、誰の何分を節約するかを数字で決め、7〜14日で最小の完成形を作って、先に課金を通します。最後に集金・監視・サポートを自動化して手離れ化すると、月5万円が続きやすくなります。
スクレイピングで稼ぐはアリ?
スクレイピングで稼ぐこと自体は「絶対にダメ」とは言えませんが、主軸にするのはおすすめしにくいです。理由は、相手サイトの規約や負荷、著作権や個人情報などの地雷が多く、ある日突然「アクセス遮断」「アカウント停止」「炎上」で止まりやすいからです。
どうしても使うなら、公式APIや公開データを優先し、取るデータと取り方を小さくして、守るべき実装(レート制限・キャッシュ・再試行・監視)までセットで作るのが現実的です。
スクレイピングが危険になりやすいケース
大きく3つあります。1つ目は「相手が止めたくなる取り方」をすると、技術的に遮断されやすいことです。たとえば政府のAPIでも、負荷状況によってアクセス制限をかけることがあると利用規約に書かれています。相手が“公式に用意した窓口”ですら制限があるなら、画面を直接取りに行くスクレイピングは、より止められやすいと考えるのが自然です。
2つ目は、ログインが必要な場所を自動で取りに行ったり、認証やアクセス制御を回避したりすると、不正アクセス禁止法の問題に近づくことです。
3つ目は、取った内容をそのまま転載・再配布すると、著作権(複製や公衆送信など)や権利処理の問題になりやすいことです。
商品一覧や記事本文を大量に取得して自サイトに“ほぼそのまま”載せる、価格比較のために短時間で何千回もアクセスする、会員ページを自動巡回する、といった動きは、遮断・通報・揉め事につながりやすいです。
代替案:公式API/公開データ/提携/ユーザー入力で回避する
「最初から“取っていい道”が用意されていることが多い」からです。たとえば政府統計にはAPIがあり、利用規約の中でルールや制限の考え方が示されています。
また法人情報のように、公式にAPIで提供されているデータもあります。
公開データについては、国が公共データの利用ルール(公共データ利用規約)を整備していて、出典表示や第三者権利への注意など、最低限の守るべき点が整理されています。
「価格監視」をやりたいなら、まず公式APIがあるサービスだけを対象にする、「統計レポート販売」をやりたいならe-Stat APIから取る、「企業リスト作成」をやりたいならgBizINFO APIを使う、どうしても画面しかない場合は“提携して取得許可をもらう”か、“ユーザーが自分のデータを入力する形式”にして、スクレイピング依存を減らす、といった回避ができます。
取得データの権利・個人情報・利用目的
スクレイピングは「集める」より「使う」で事故が起きやすいからです。個人情報保護法では、個人情報や個人データの定義があり、公開されている情報でも個人情報になり得ることが示されています。
さらに、企業が“特定の相手に提供するために管理しているデータ”は、不正競争防止法の「限定提供データ」として保護の枠組みがあり、経済産業省が指針を出しています。
つまり「見える=自由」ではなく、「何を」「何のために」「どう管理して」使うかが問われます。
問い合わせフォームやSNSから個人の連絡先っぽい情報を集めて営業リストにする、病歴・思想・信条など“要配慮に近い情報”を含む投稿を集めて分析サービスとして売る、サイト上の文章や画像をそのまま再配布してしまう、会員限定のデータを“みんな見れるデータ”として扱ってしまう、などです。こういう形は、クレームや炎上だけでなく、法務・運営コストが跳ね上がりやすいです。
守るべき実装
技術的に“相手を壊さない・自分も壊れない”設計にしないと、止められるからです。robots.txtの考え方(自動クライアントがどうアクセスしてよいかの指示)は標準化されており、エラー処理やキャッシュの扱いまで含めて仕様が整理されています。
また、多くのAPIでは、混雑時に429(リクエスト過多)が返る前提で、指数バックオフで再試行するよう推奨しています。
最低限これだけは入れておくと「止まりにくさ」が上がります。アクセス間隔を自動で調整して短時間に集中しないようにする、同じデータを何度も取りに行かないようキャッシュする、429や一時エラーが出たら指数バックオフで再試行する、失敗が続いたら自動で止めて通知する(監視)、という形です。これを入れないと、相手に負荷をかけて遮断されるか、自分のサービスが不安定になります。
“主軸”にしにくい理由と、どうしても使う場合の安全策
「相手都合で突然変わる」からです。画面のHTMLが少し変わるだけで壊れますし、規約やアクセス制限の運用が変わることもあります(公式APIでも負荷で制限すると明記されるくらいです)。
さらに、ログインやアクセス制御の回避に近づくほど、不正アクセス禁止法リスクが上がります。
データの側も、限定提供データの考え方や、個人情報の扱いに引っかかると、ビジネスとして継続が難しくなります。
「どうしてもスクレイピングが必要」なケースは、社内で自社のページ死活監視をする、提携先が“画面でしか出せない”情報を許可の上で取る、研究用途で極小規模に試す、などに寄せると安全側です。その場合の安全策は、まず相手の明確な許可や利用条件に合わせる、取る量を最小にする、個人情報になり得るものは原則取らない(または匿名化と利用目的の固定、保存期間の短縮まで決める)、robotsの指示とレート制限・キャッシュ・再試行・監視を実装する、そして「転載」ではなく“集計結果や指標”として提供する、という形です。
必要なら、危険度のざっくり判断は次の表で整理できます。
| やりたいこと | 危険度 | ざっくり理由 |
|---|---|---|
| 公式APIで取得してレポート化 | 低 | 取ってよい窓口とルールがある |
| 公開データを規約に沿って利用 | 低〜中 | 出典表示や第三者権利に注意が必要 |
| 公開ページを低頻度で監視(死活など) | 中 | 仕様変更とアクセス負荷に注意 |
| 会員ページ・ログイン後を自動取得 | 高 | 認証・不正アクセスに近づく |
| 取得内容をほぼそのまま転載・再配布 | 高 | 著作権・権利処理で揉めやすい |
| 限定提供データっぽいものを収集・販売 | 高 | 不正競争の枠組みに触れやすい |
まとめ
スクレイピングで稼ぐのは「できる場合もある」けれど、規約・負荷・転載・個人情報・不正アクセスのリスクが重なりやすく、安定収益の主軸にしにくいです。まずは公式APIや公開データ、提携、ユーザー入力など“安全な道”を優先し、どうしても必要なときだけ、取る量を小さくして、レート制限・キャッシュ・再試行・監視まで含めて設計するのが堅い選択です。
Python自動収益の運用を最小化する「やり方」:土日・週1でも回る設計

- Pythonを使った自動化のやり方
- 自動化のサンプルコードを“収益化プロダクト”に育てる方法
- 土日だけで進める開発スケジュール
- Pythonの副業を週1運用で回す仕組み
- Python副業のロードマップ
Pythonを使った自動化のやり方
Pythonの自動化は、「決まった時間に動かす」→「データを処理する」→「結果を知らせる」の3つに分けると、最小の形で安全に作れます。
この3つをちゃんと分けておくと、後から機能を増やしても壊れにくく、収益化の仕組み(レポート配信、監視SaaS、業務自動化)にもつなげやすいです。
定期実行の選択肢
「どこで動かすか」で安定性と手間が変わるからです。いちばん昔からあるのはcronで、分・時・日などの5つの欄で実行タイミングを決めます。これはLinuxのマニュアルにも整理されています。
一方で、コードを置いている場所で定期実行したいなら、GitHub Actionsのスケジュール実行が便利です。POSIXのcron書式でUTC時刻を指定でき、最短間隔は5分で、既定ブランチの最新コミットを元に動く、という特徴があります。
サーバを持ちたくないなら、サーバレスのスケジューラを使う方法があります。たとえばAWSでは、EventBridge Schedulerでcronやrate式のスケジュールを作り、Lambdaを呼び出せます。 またGoogle Cloud Schedulerもcronジョブを作れますが、「まれに同じジョブが複数回呼ばれることがあるので、処理は同じことを2回やっても困らない作り(冪等)にしてね」と明記されています。Azureでもタイマーで関数をスケジュール実行できます。
最初の選び方はこうすると失敗しにくいです。自分のPCを毎日つけっぱなしにしないなら、cronを自宅PCで回すより、VPSやクラウドに置くほうが安定します。コードがGitHubにあり、1日1回のレポート作り程度なら、GitHub Actionsのスケジュールで十分なことが多いです。外部に公開する監視や通知など「止まると困る」用途なら、EventBridge Scheduler+LambdaやCloud Schedulerなど、運用を任せられる仕組みが向きます。
| 選択肢 | 強み | 弱み | 典型の用途 |
|---|---|---|---|
| cron(サーバ上) | 仕組みがシンプルで速い | サーバ管理が必要 | 毎朝の集計、定期バックアップ |
| ワークフロー(例:GitHub Actions) | コードと一緒に管理できる | 実行はUTCや制約に注意 | 定期レポート生成、軽いバッチ |
| サーバレス(例:Lambda+スケジューラ) | サーバ管理がほぼ不要 | 失敗時の再実行設計が必要 | 監視・通知、SaaSの定期処理 |
データ取得→整形→保存
「データ取得」はネットワークや相手都合で失敗しやすく、しかも“途中までできた状態”がいちばん危険だからです。失敗したときにやり直すなら、再試行(リトライ)は定番ですが、Google Cloudのドキュメントでも「リトライは指数的に待ち時間を増やす方法(exponential backoff)を使い、同じ操作を繰り返しても安全な場合(冪等性の条件)にだけ使うのが基本」と説明されています。
また、スケジューラ側の事情で同じ処理が複数回呼ばれる可能性があるなら、なおさら「2回動いても結果が壊れない保存の仕方」が必要です。
失敗しにくい流れは「取得→整形→保存」をさらに細かく分けます。まず取得した生データは、そのまま“作業用の場所(ステージング)”に保存します。次に整形して、行数や必須項目があるかなど簡単なチェックをします。最後にチェックを通ったものだけを“本番の保存場所”に置き換えます。こうすると、途中で落ちても本番データは前回の成功分が残り、サービスが止まりにくいです。さらに「最後に成功した日時」を一緒に保存しておくと、次回はそこから先だけ処理でき、ムダな再処理も減ります。
通知設計と「見落とさない」ルール
通知が多すぎると人は見なくなるからです。SlackのIncoming Webhooksは、WebhookのURLにJSONを送るだけでメッセージを投稿できる仕組みとして説明されています。 ただしSlackにはレート制限があり、超えるとHTTP 429が返ってきて、Retry-After(何秒待てばいいか)が返されます。
メール通知も強力で、PythonにはSMTPでメールを送るための標準モジュールが用意されています。 量が増えるなら、Amazon SESのようにSMTPやAPIで送れるサービスもあります。
「見落とさない」ためのルールはシンプルにします。ふだんは通知しないで、異常だけ鳴らす(エラー、数値の急変、期限切れなど)。通知文には「何が起きたか」「どのデータか」「いつの実行か(run_idや日時)」「次に何をすればいいか」を入れます。Slackは短文+重要な数字、メールは長文で経緯も書く、のように役割を分けると混乱が減ります。レート制限に当たったらRetry-Afterの秒数だけ待って再送する設計にしておくと、通知が欠けにくくなります。
ログ・リトライ・冪等性
「何が起きたか分からない自動化」は、直すのに一番時間がかかるからです。Pythonのloggingは、アプリの出来事を柔軟に記録する仕組みとして標準で用意されています。
またリトライは便利ですが、やみくもに連打すると相手にも自分にも負担になります。そこで指数バックオフ(待ち時間をだんだん増やす)やジッター(少し揺らす)を使うのが基本だと、Googleのドキュメントで説明されています。
さらに、スケジューラの事情で“同じ処理が複数回呼ばれることがある”なら、同じ入力に対して同じ結果になるように作る(冪等性)ことが推奨されています。
止まりにくい作りは次の発想です。まずログには「開始」「成功」「失敗」「処理件数」「かかった時間」を必ず残します。次に、ネットワークの取得は失敗する前提で、指数バックオフで数回だけ再試行します。最後に冪等性として、「同じ日付のレポートは同じファイル名にして上書きする」「同じ通知はrun_idで二重送信を防ぐ」「保存前に“もう保存済みか”を確認する」などを入れます。これで、二重実行や一時エラーが起きても、結果がぐちゃぐちゃになりにくいです。
小さく始めるテンプレ構成
最初から大きく作るほど、運用の穴(通知がうるさい、データが壊れる、実行環境が変わる)が増えるからです。たとえばGitHub Actionsのスケジュールは、UTCで動き、既定ブランチの最新コミットで走るなどクセがあります。最小構成で動かしてクセを先に知っておくほうが安全です。
また、クラウドのスケジューラは「まれに複数回呼ばれるかも」と前提が書かれているので、最小のうちに冪等性を入れておくと、後から慌てなくてすみます。
後で拡張しやすい最小テンプレは「役割で分ける」だけで十分です。たとえば、実行する入口(scheduler設定)、処理本体(worker)、通知(notifier)、設定(config)、ログの出力先、を分けます。ファイル構成のイメージは次のようにしておくと、監視SaaSや定期レポート販売の“裏側”として、そのまま育てやすいです。
| 部品 | 役割 | 最初に入れる中身の例 |
|---|---|---|
| scheduler | 定期実行の設定 | cron / Actions / スケジューラ設定 |
| worker | 取得→整形→保存 | 入力・出力・チェックの最小処理 |
| notifier | Slack/メール通知 | 成功は静か、失敗は通知 |
| state | 前回の成功情報 | 最終成功日時、処理済みID |
| logs | 何が起きたか | 1行で追えるログ |
まとめ
Pythonの自動化を最小で作るなら、「定期実行→処理→通知」の3点セットにして、さらに「ログ」「リトライ」「冪等性」を最初から少しだけ入れるのがコツです。
定期実行はcron・ワークフロー・サーバレスで選び方が変わり、データ処理は“途中で落ちても壊れない保存”が重要になります。通知は鳴らしすぎない設計にして、Slackのレート制限やメール送信の仕組みも前提に置くと、見落としが減ります。
この形ができると、定期レポート配信や監視通知のような「自動で回る副業」に、そのままつなげられます。
自動化のサンプルコードを“収益化プロダクト”に育てる方法
サンプルコードを「お金を生むプロダクト」にするには、動くだけの状態から、「他人が迷わず使えて」「勝手に壊れにくく」「無断利用されにくい」状態へ段階的に育てるのが近道です。
そのために必要なのは、入力と出力の設計、例外処理とログ、設定の外出し、認証と利用制限、テストと監視、そして配布形態(スクリプト/Webアプリ/API)の選び分けです。
サンプル→MVPにするための差分
サンプルは「作者が分かっている前提」で作られていることが多く、他人が使うと入力ミスや環境差で簡単に止まるからです。定期実行を使う場合も同じで、たとえばGitHub Actionsのスケジュール実行は、UTC時刻のcron書式で動き、最短間隔が5分で、既定ブランチの最新コミットを使うなどのルールがあります。こうした前提を知らないと「動くはずなのに動かない」事故が起きやすいです。
MVPでは「入力は1種類に固定する」「出力は1つの形式に固定する」「失敗したら必ず分かる」を最優先にします。たとえばCSVを受け取って集計し、PDFを1枚だけ出すプロダクトなら、CSVの必須列が足りないときに“どの列が足りないか”をメッセージで返し、処理が途中で止まったときは“どこまでできたか”をログに残します。これだけでも購入者の不満は大きく減り、「サンプル」から「商品」に一歩近づきます。
設定ファイル化・UI化で「他人が使える」形にする
収益化では「あなたが毎回設定してあげる」状態だと、顧客が増えるほど手間が増えて利益が消えるからです。設定をコードに埋め込むのではなく、環境変数や設定ファイルへ外出しする設計が基本になります。Pydantic Settingsは環境変数やシークレットファイルから設定を読み込む仕組みとして整理されていて、FastAPI側も設定管理にPydantic Settingsを使う考え方を明確にしています。
同じスクリプトでも「URLやトークンをコードに直書き」から「.env(または環境変数)に入れて読み込む」に変えるだけで、購入者が使いやすくなります。さらに一歩進めるなら、最初はCLI(コマンド)で「入力ファイルの場所」と「出力先」だけ選べるようにし、売れ始めたら簡単な画面(フォーム)を付けます。UIを付ける目的はカッコよさではなく、「迷う場所を減らす」ことです。
利用制限・認証・APIキー
収益化すると「ただ乗り」や「なりすまし」も現実に起きるからです。OWASPのAPI Security Top 10 2023では認証まわりの失敗(Broken Authentication)が重要リスクとして挙げられており、認証の境界や実装ミスが狙われやすいことが説明されています。
また実装面では、FastAPIにはヘッダーでAPIキーを受け取る仕組み(APIKeyHeader)が用意されていて、APIキー方式を組み込みやすい設計になっています。
まず「無料版」と「有料版」を分けたいなら、無料版にはAPIキーを発行せず、使える回数や対象件数を小さくします。有料版ではAPIキーを発行し、キーごとに回数や機能を変えます。さらに安全にするなら、APIキーはいつでも再発行できるようにして、漏れたときにすぐ止められる仕組みにします。ここまでやると、無断利用が起きても“止血”ができ、売上が急にゼロになりにくくなります。
テストと監視
プロダクトは「壊れた瞬間に収益が止まる」からです。テストは、壊れていないことを毎回確かめるための仕組みで、pytestは標準のassertで期待値を確認できることや、安定したテスト環境を作るためのfixtureの考え方を公式に整理しています。
監視は、壊れたときに気づける仕組みで、SentryはPython向けにエラーや性能情報を収集するSDKとモニタリングの考え方を提供しています。
まず「入力が正常なら出力が出る」「入力が壊れていたら分かりやすく失敗する」「同じ入力を2回流しても結果が壊れない」をpytestで自動チェックします。次に本番では、例外が出たらSentryへ通知し、毎日の定期処理が成功したかどうかを“必ず見える場所”に残します。これを入れるだけで「気づいたら3日止まっていた」事故が激減し、結果として解約も減ります。
配布形態の選び方
配布形態によって「手離れ」「守りやすさ」「顧客の使いやすさ」が変わるからです。スクリプト販売ならPythonパッケージとして配る設計が取りやすく、pyproject.tomlにメタデータを置く考え方(PEP 621)や、pyproject.tomlの書き方はPython Packaging User Guideで整理されています。
一方、PCにインストール不要で使わせたいなら、PyInstallerで実行ファイル化する方法があり、onefile(単一ファイル)やonedir(フォルダ配布)の選択肢が明記されています。
APIとして提供するなら、FastAPIのセキュリティ機能(apiKeyをヘッダーやクエリなどで扱う仕組み)が公式に整理されています。
判断の目安は次のようになります。
| 配布形態 | 向いているケース | つまずきやすい点 |
|---|---|---|
| スクリプト販売(パッケージ) | 開発者・社内SEが顧客で、カスタム前提でもOK | 環境差で動かないとサポートが増える |
| 実行ファイル販売(PyInstaller) | 非エンジニアにも配りたい、社内PCで動かしたい | OS差分やアンチウイルス誤検知などに注意 |
| Webアプリ | いつでも最新版を使わせたい、運用をこちらで管理したい | サーバ費用と運用責任が増える |
| API提供 | 他社ツールから使わせたい、従量課金にしたい | 認証・制限・監視が必須で守りが重い |
たとえば、最初はスクリプト販売で「買われるか」を確かめ、売れ始めたらWebアプリ化してアップデートの手間を減らし、需要が広がったらAPIを公開して従量課金にする、という順番にすると失敗しにくいです。
まとめ
サンプルコードを収益化プロダクトに育てるには、「動く」だけでは足りません。入力と出力を固定し、例外処理とログで止まり方を分かりやすくし、設定を外出しして他人が使える形にします。次に、APIキーなどで無断利用を防ぎ、テストと監視で“壊れたら気づける”状態を作ります。最後に、スクリプト・実行ファイル・Webアプリ・APIのどれで配るかを決めると、手離れと収益の安定が一気に上がります。
土日だけで進める開発スケジュール
土日だけでPython副業を進めるなら、「毎週同じ型で動く」ように作業を固定し、機能を1つに絞って、先に販売導線まで通すのが最短です。
MVP(最小の完成形)は、立派さより「学べること」を優先し、売れるかどうかを早く確かめます。これは、作ってから後悔する時間を減らすためです。
土日にやる作業を固定化
土日だけだと「迷う時間」が一番ムダになりやすいからです。毎週の作業を同じ順番にすると、少ない時間でも前に進みます。さらに、作って測って学ぶ(Build-Measure-Learn)の形にすると、週末ごとに改善がしやすくなります。
2週間(週末2回)で回すなら、次のように「型」を決めてしまうのが分かりやすいです。
| 日程 | 設計 | 実装 | 公開 | 検証 |
|---|---|---|---|---|
| 1週目 土曜 | 誰の何分を減らすかを1つに決める | コア処理だけ作る | まだ出さない | 途中でも動くか確認 |
| 1週目 日曜 | 例外時の動きと出力を決める | 最小のUI/入力(CLIやフォーム)を足す | テスト公開 | 1〜3人に使ってもらう |
| 2週目 土曜 | 直すのは「困った点」だけに絞る | 改善して安定化 | 本公開 | 反応を数字で見る |
| 2週目 日曜 | 次の改善を決める | 自動化(通知やログ)を足す | 販売導線を整える | 継続の仕組み化 |
ここで大事なのは、毎回「設計→実装→公開→検証」を全部やることです。どれかが抜けると、次の週末に何をすべきか分からなくなりがちです。
“作らない”判断を早くする要件
「作ったけど欲しがられなかった」が一番の損だからです。スタートアップの失敗理由として「市場に必要とされない(No market need)」が大きい、という分析がよく引用されます。
土日だけの副業は、ここで遠回りすると戻れません。だから最初から「1機能だけ」の要件にします。
「これ以外は作らない」を先に決めます。たとえばレポート系なら「CSVを入れたら、1枚のPDFが出る」だけにします。監視系なら「指定したページの更新が止まったら通知する」だけにします。ここでの要件は、入力が1つ、出力が1つ、失敗したら分かる、の3つを満たせば十分です。
先に販売導線を用意
MVPは「作ること」より「確かめること」が目的だからです。MVPは価値の仮説を試すための“最小の形”で、早く反応を集めるほど判断が速くなります。
販売導線(LP・デモ・予約)がないと、反応が取れず、学びも残りません。
LPは“きれい”より“分かる”を優先します。土日の副業なら、静的サイトでサクッと出せる形が相性が良いです。GitHub Pagesは、リポジトリのHTMLなどから静的サイトを公開できる仕組みとして説明されています。
LPに入れる内容は、「誰の」「何分を」「どう減らすか」と「見本(デモ画像や短い動画)」、そして「申し込み(予約・無料体験)」だけにして、まず“欲しい人がいるか”を確かめます。
MVPの完成条件
完成の線がないと、いつまでも作り続けてしまうからです。Build-Measure-Learnの考え方では、作ったら必ず測って学び、次の一手を決めます。
つまりMVPの完成は「機能がそろった」ではなく「判断できる数字が集まった」です。
土日だけでも測れる条件にします。次の表は、どのモデルでも使える“成功の定義”の例です。
| 目的 | 計測する数字 | 7〜14日での合格ライン例 |
|---|---|---|
| 需要があるか | LPの申し込み数 | 10件以上で次に進む |
| お金が出るか | 予約や事前決済の数 | 1〜3件でも出たら強い |
| 役に立ったか | 「続けて使いたい」返事 | 3人中2人がYES |
| 続けられるか | 週末だけで運用できたか | 手作業が多すぎない |
合格ラインは高すぎなくて大丈夫です。最初は「ゼロじゃない」を確認するだけでも価値があります。
継続改善のバックログ
週末だけだと“全部やる”は不可能だからです。だから改善は、売上に直結する順に並べて、上から潰します。
また、定期実行や通知のような自動化では、まれに同じ処理が重なって動くことがあるので、2回動いても結果が壊れない(冪等)にするのが安全です。Cloud Schedulerのドキュメントでも、まれに同じジョブが複数回リクエストされる可能性があるので、ハンドラは冪等にするべきだと説明されています。
バックログ(やることリスト)を次の3つに分け、順番を固定します。まず「売れるための改善」(LPの言い回し、デモの追加、価格の分かりやすさ)を一番上に置きます。次に「解約を減らす改善」(エラー時の分かりやすさ、入力ミス防止)を置きます。最後に「手離れ改善」(定期実行、ログ、通知、自動回復)を置きます。
この順番にすると、土日だけでも収益が先に立ちやすく、後から自動化でラクにできます。
まとめ
土日だけでPython副業を進めるなら、作業の型を固定し、機能を1つに絞り、先に販売導線を用意して、数字で判断できるMVPを作るのが近道です。
MVPは立派さより検証が目的なので、完成条件を「判断できる数字が集まった」に置き、週末ごとに改善を回します。運用を自動化するときは、同じ処理が重なっても壊れない作りを意識すると、収益が止まりにくくなります。
Pythonの副業を週1運用で回す仕組み
Python副業を「週1のチェックだけ」で回すことは可能です。ポイントは、ふだんは自動で動き、危ないときだけ知らせてくれる形にすることです。
そのために必要なのは、監視とアラート(異常のお知らせ)を先に作ること、サポートを減らす仕組み(FAQや最初の説明)を用意すること、コストが暴走しない上限を決めること、そして事故が起きたときの戻し方(バックアップ・ロールバック)を決めておくことです。
週1で済む運用項目
毎日見なくても、異常を自動で拾える仕組みがあれば「人が見るのは週1で十分」になりやすいからです。たとえば、クラウドの定期実行は「必ず1回は動く(at least once)」設計のものがあり、まれに同じ予定で複数回動くこともあるので、仕組み側に“壊れない作り”を入れておくのが前提になります。
週1運用にするときの「固定の確認項目」を、最初から決めておくと迷いが減ります。たとえば毎週日曜の朝に30〜60分だけ、次の表の順で見ます(同じ順番が大事です)。
| 週1で見るもの | 見る理由 | 具体例(OK/NGの判断) |
|---|---|---|
| ① 稼働(動いてる?) | 止まっていたら売上が止まる | 「今週の定期処理が全部成功」ならOK、「失敗が1回でもある」なら原因を見る |
| ② お金(急に増えてない?) | 気づくのが遅いと赤字になる | 先週より急に増えたら、ログ量やメール量を疑う |
| ③ 問い合わせ(同じ質問が多い?) | FAQにすると一気に減る | 同じ質問が3回出たらFAQへ追加する |
| ④ 改善(次に何を直す?) | 週末にやることを迷わない | 「売上に近い改善」だけ先にやる |
| ⑤ バックアップ確認 | 事故のとき戻せる | バックアップが最新ならOK、古いなら直す |
監視とアラート
アラートは「原因」より「症状」で出したほうが、見落としが減り、行動しやすいからです。Googleのインシデント対応の考え方でも、アラートはユーザー影響に近い症状で、行動できる(actionable)ものにするのが重要だと整理されています。
また、定期実行は“まれに2回動くことがある”前提があるので、同じ通知が2回飛んでも困らないようにしたり、同じ処理が2回走っても結果が壊れないようにする考え方(冪等)が必要です。
週1運用で現実的なアラートの線引きは「放置すると売上や信用が減るものだけ、即時通知」です。たとえば定期レポート販売なら「レポートが作れなかった」「メールが送れなかった」「出力ファイルが空だった」を即時通知にします。逆に「処理が少し遅い」などは、週1のレポートでまとめて見れば十分です。こうすると通知がうるさくならず、重要な通知だけが目に入ります。
サポート工数を減らす
買った人は「まず自分で解決したい」ことが多く、自己解決の場がないと問い合わせが増えて、週1運用が崩れるからです。Microsoftの調査では、ブランドや組織に「自己解決の場(ポータルやFAQ)」があることを多くの消費者が期待している、といった結果が示されています。
サポートを減らす最小セットは「最初の1枚」と「FAQの3つ」と「短い動画(または画像付き手順)」です。最初の1枚には、使い方の流れ、よくある失敗(入力ファイルの場所、権限、文字コードなど)、困ったときの確認ポイントだけを書きます。FAQは、実際に来た質問から増やします(想像で増やすと外れます)。動画は長くしないで、2〜3分で「ここを押す」「ここに入れる」「ここを見る」だけにします。これだけで、同じ質問のループが減り、週1の確認で回りやすくなります。
コスト上限の設計
週1運用で一番怖いのは「知らないうちにコストが増えること」だからです。たとえばAWS Lambdaには無料枠(毎月の無料分)があり、小さな処理なら無料枠で収まる可能性がありますが、使い方次第で課金は増えます。
メール送信も、Amazon SESのように「送った分だけ」の料金設計で、1,000通あたりの単価が明記されています。
ログも油断すると増えやすく、CloudWatchでは取り込み量に応じた費用がかかることが示されています。
だからこそ、AWS Budgetsのような仕組みで「今月はいくらまで」と決め、近づいたらアラートを出すのが有効です。
コスト上限は「数字で決めて」「止め方も決める」と事故が減ります。たとえば、月の上限を小さく置き、50%・80%・100%で通知が来るようにします。ログは保存期間を短めにして、必要以上に貯めないようにします。メールは「異常だけ送る」「成功は週1まとめ」にすると通数が減ります。さらに、エラー監視ツール(例:Sentry)のように、イベント量で課金され、上限予算を設定できるタイプを使うと、暴走しにくいです。
| コスト源 | ありがちな増え方 | 週1運用向けの上限ルール例 |
|---|---|---|
| 実行回数 | バグで無限ループ的に呼ばれる | 予算アラート+異常回数で停止 |
| ログ | 失敗ログが大量に出る | 保存期間を短く+エラー時だけ詳細 |
| メール | 成功通知を毎回送る | 失敗だけ即時、成功は週1まとめ |
| 外部API | 取り直しが多い | キャッシュで回数を減らす |
事故対応の型
どんなに気をつけても障害は起きるので、起きたときに「早く戻す型」を持っているかで被害が変わるからです。Googleのインシデント対応のガイドでは、影響を小さくするために、アラート、役割分担、素早い対応、そして学び(振り返り)まで含めた流れが重要だと整理されています。
ロールバック(元に戻す)も、仕組みとして用意できます。たとえばAWS Lambdaでは、エイリアスの重み付けで新旧バージョンにトラフィックを分け、問題があれば素早く戻す考え方が説明されています。
データのバックアップも、S3のバージョニングのように「消した・上書きした」を戻せる仕組みが用意されています。
| タイミング | やること | 具体例 |
|---|---|---|
| 気づいた直後 | まず被害を止める | 新版を止めて旧版へ戻す、送信を一時停止する |
| 10〜30分以内 | 何が起きたかを短く共有 | 「いつから」「誰が困る」「今の対処」を1枚にまとめる |
| 当日中 | 直したか確認する | 監視で正常に戻ったかを確認し、同じ通知が再発しないか見る |
| その後(週1枠でOK) | 振り返りを書いて次を決める | 原因、影響、対処、再発防止を残す |
ここでのコツは「原因探しより、まず復旧」です。原因はあとで落ち着いて見ればよく、先に戻せる仕組み(旧版が残っている、データが戻せる)があると、週1運用でも十分戦えます。
まとめ
Python副業を週1運用で回すには、毎日がんばるのではなく、仕組みで“普段の手間”を消すのが近道です。週1で見る項目を固定し、アラートは「症状ベースで行動できるもの」だけにし、FAQや短い説明で問い合わせを減らし、予算アラートでコスト暴走を止めます。最後に、バックアップとロールバックの型を用意しておけば、事故が起きても戻せます。
Python副業のロードマップ
Python副業で「自動収益」まで行く最短ルートは、いきなり大きな仕組みを作ることではありません。まずは小さな自動化で「価値が伝わる成果物」を作り、次にAPI・DB・デプロイの最低限を身につけて案件化し、その後に継続課金(SaaSや定期レポート)へ育てる流れが現実的です。
この順番にすると、途中で止まりにくく、収益が「単発」から「積み上げ」に変わっていきます。
未経験:まず作るべき“価値が伝わる”小自動化
「副業ニーズが増えているのに、最初から大きな開発をすると失敗しやすい」からです。総務省の就業構造基本調査では、非農林業従事者のうち副業がある人は305万人、追加就業希望者は493万人と示されています。つまり「今の仕事にプラスして収入を作りたい人」が多い状況です。
この段階で強いのは、難しいサービスより「一発で便利さが伝わる小自動化」です。便利さが伝われば、次の学習も続きやすくなります。
「毎週の売上CSVを入れると、合計・前年差・上位商品だけを自動でまとめて出す」「毎日1回、特定の更新が止まったら通知する」「面倒なファイル名変更やフォルダ分けを自動でやる」などが向いています。ポイントは、相手が見た瞬間に「助かる」が分かることです。
初心者:API・DB・デプロイの最低限
「収益化は、作ったものを安定して届けるところまでがセット」だからです。ネットでの取引が伸びている今、商品やサービスをオンラインで届ける土台は強くなっています。経済産業省の調査では、2024年の国内BtoC-ECは26.1兆円、BtoB-ECは514.4兆円まで拡大しています。
さらに、決済も広がっていて、2024年のキャッシュレス決済比率は42.8%(141.0兆円)とされています。
つまり「ネットで申し込み、ネットで支払い、ネットで受け取る」流れが当たり前になっているので、API・DB・デプロイができると収益化の形が一気に増えます。
最初はこの3点だけ押さえると、売り物にしやすくなります。APIは「外部サービスとつながる入口」、DBは「データを安全に保管する箱」、デプロイは「相手がいつでも使える場所に置くこと」です。たとえば「毎日データを集めてダッシュボードを更新する」なら、APIで取得してDBに保存し、クラウド上で動かして見せる形にすると“仕事っぽい成果物”になります。
この段階の最低限を、見やすくすると次の表のイメージです。
| できるようにすること | なぜ必要か | すぐ役立つ例 |
|---|---|---|
| APIで取得 | データを集められる | 定期レポートの自動更新 |
| DBに保存 | 後から追える | 過去比較・異常検知 |
| デプロイして動かす | 相手が使える | 週1運用の小SaaS |
案件化:業務改善を売る
「会社が欲しいのはコードではなく、時間が減る成果」だからです。IPAの調査では、DXの成果が出ている企業ほどデータ利活用が進んでいるとされ、成果が出ている企業ではデータ利活用(全社+部署)が合計で7割超という説明があります。
つまり、データを集めて整えて使える形にする仕事は、現場の価値になりやすいです。ここにPython自動化は直球で刺さります。
案件の売り方は「成果物」「価格」「保守」を最初からセットにすると安定します。たとえば「毎週の報告書作成を自動化して、作業時間を短縮する」「在庫チェックと通知を自動化して、見落としを減らす」など、相手の“ムダ時間”を減らす形で提案します。成果物は「動くもの」と「説明書」を含め、価格は作成費+月額保守(小さくても良い)にすると、単発で終わりにくくなります。
継続課金:SaaS/レポート化へ拡張する手順
継続課金にすると「同じ労力でも収益が積み上がる」からです。取引のオンライン化と決済の普及は、継続課金の土台になります。BtoB-ECが大きく伸びていることは、企業側がオンラインで申し込み・継続利用する流れが強いことの裏付けになります。
そして、運用を自動化するときは「同じ処理がまれに複数回動く前提」を知っておくのが重要です。たとえばCloud Schedulerは“at least once”配信で、まれに同じスケジュールで複数回動く可能性があるので、繰り返し実行されても問題が出ない作り(冪等)を求めています。
継続課金は「止まらない作り」ができた瞬間に、現実味が一気に上がります。
単発案件で作った自動化を「型」にして、複数社に同じ仕組みで提供します。レポートなら、毎週自動生成して配信し、月額にします。監視SaaSなら、更新停止やエラーだけ通知し、対象数に応じて月額にします。最初から完璧を目指すより、「1社で動いた型」を作って横展開する方が早いです。
Python副業案件の取り方
「仕事は信用で決まりやすい」からです。フリーランス市場が大きくなる一方で、競争も強いことが示されています。たとえばフリーランス人口や市場規模の推計を公表する調査もあり、働き方として広がっていることが分かります。
また、取引面ではフリーランスが安心して働ける環境づくりとして、フリーランス関連法が2024年11月1日に施行された旨が案内されています。条件の明示や支払いなど、取引を「言った言わない」にしない流れが強まっています。
つまり、実績の見せ方と、条件を文書で固める動きがますます大事になります。
案件獲得は「小パッケージ化」が効きます。たとえば「レポート自動化パック」「監視通知パック」「集計ダッシュボードパック」のように、やること・出すもの・費用・保守の有無を最初から固定して見せます。実績は、派手なサービスより「誰の何分を減らしたか」を数字で書ける成果物が強いです。さらに安全面では、「簡単に稼げる」系のうまい話は避けます。消費者庁は、簡単な副業をうたい高額なサポート契約をさせる事業者への注意喚起を公表しています。
地味でも「ちゃんと役に立つ自動化」を積み上げた方が、長く稼げます。
まとめ
Python副業は、未経験でも「小さな自動化」から入り、API・DB・デプロイの最低限を覚えて案件化し、その成果を型にして継続課金へ育てるのが王道です。オンライン取引と決済が広がっている今は、仕組み化と相性が良い環境です。ただし、継続課金は「止まりにくい作り」が前提になるので、冪等性や監視など運用も最初から意識すると収益が止まりにくくなります。最後は、実績を小パッケージとして見せ、条件は書面で固める。この流れで「単発→積み上げ」へ移れます。
Python自動収益のリスク回避・周辺スキル・よくある疑問

- 規約・法務・セキュリティ
- 収益化に必要な周辺スキル
- Python副業 稼げないと言われる理由と、再現性を上げる改善策
規約・法務・セキュリティ
Pythonの自動化で収益を作るときに一番こわいのは、「作れないこと」より「止められること」です。規約違反でアカウント停止(BAN)になったり、個人情報の扱いで炎上したり、返金トラブルで信用が落ちたりすると、売上が一気にゼロになりやすいからです。
だから最初にやるべきは、稼ぐ仕組みを作る前に「守る線」を決めることです。SNS・スクレイピング・自動投稿は規約で止められやすい場所が多いので、やるなら範囲を小さくし、公式の許可がある方法を優先し、個人情報とお金の部分は“事故らない設計”にします。
規約違反になりやすい自動化
「プラットフォームは“自動で増やす行為”にとても厳しい」からです。たとえばXの公式ルールでは、無差別・大量の自動フォロー/アンフォローはダメだとはっきり書かれていて、フォロワーを増やすと称するアプリ自体も禁止だと説明されています。
Meta側も、自動でデータを集める行為は“明確な許可が必要”という形で条件を置いています。
さらにInstagramは、データスクレイピングが規約に反するとして、アカウント制限の理由として説明しています。
広告収益を狙う自動化でも、YouTubeは「本物の視聴者の関心に基づかない動き(無効なトラフィック)」を問題として例を挙げています。
検索流入を狙う場合も、Googleは“順位操作が目的の大量生成コンテンツ”をスパムとして示しています。
SNSで自動いいね・自動フォロー・自動DMを回して集客しようとすると、短期で数字が動いても、凍結や制限で一気に終わることがあります。スクレイピングでも、「robots.txtに書いてないからOK」という考え方は危険です。robots.txtは“お願いのルール”であって“許可証”ではない、と仕様の中で明確にされています。
安全側に寄せるなら、最初から「公式APIがある対象だけ」「許可を取れた相手だけ」「ユーザー自身が入力したデータだけ」で回る商品にすると、BAN耐性が上がります。
個人情報・機密情報の取り扱い
個人情報は「集めた瞬間」より「残したまま」が事故になりやすいからです。個人情報保護法では、使う必要がなくなった個人データは遅滞なく消去するよう努める、という考え方が示されています。
また、漏えい等で個人の権利利益を害するおそれがある場合は、個人情報保護委員会への報告や本人通知が必要になる、と整理されています。
つまり、個人情報を扱うほど、やるべきこと(消す・守る・報告する)が増えます。
よくある落とし穴は、ログにメールアドレスや氏名をそのまま出してしまうことです。エラー調査のためのログでも、必要以上に個人情報が入ると、共有や保管の難易度が上がります。もう一つ多いのが「APIキーやパスワードの置き場所」です。ソースコードや共有フォルダに鍵が混ざると、漏れた瞬間に“誰でも操作できる状態”になります。
週1運用で回したいなら、最初から「集めない」「残さない」「見せない」を基本にします。具体的には、保存するデータは最小限にし、ログはマスク(伏せ字)を標準にし、鍵は別管理にして、アクセス権を絞ります。こうすると、トラブル対応の手間も減ります。
決済・返金・特商法など最低限の確認ポイント
収益化では「コード」より「取引の説明不足」がトラブルを生むからです。特定商取引法の枠組みでは、通信販売で広告に表示すべき事項があり、違反すると行政処分や罰則の対象になり得ます。
とくに定期購入はトラブルが多く、消費者庁は最終確認画面で取引条件を明確に表示する必要がある、と注意喚起しています。
また通信販売では、一定条件のもとで商品を受け取ってから8日以内の撤回・解除(いわゆる返品ルール)が整理されています(ただし特約表示がある場合など例外もあります)。
Pythonツールを月額で売るのに「初月だけ安い」しか書かず、2か月目以降の金額や解約方法が分かりにくいと、返金・苦情・カード会社からの調査につながりやすいです。逆に最初から、料金、支払い回数、解約の手順、返金条件、問い合わせ窓口を分かる言葉でそろえておくと、サポートも減って週1運用に近づきます。
詐欺案件・誇大広告の見抜き方
「うまい話」は行政の注意喚起で何度もパターン化されているからです。消費者庁は、簡単な副業をうたい、高額なサポートプラン契約へ誘導する事業者について、相談が多数寄せられているとして注意喚起を公表しています。
さらに広告表現についても、景品表示法では有利誤認などの不当表示が問題になり、消費者庁が措置命令などを行う可能性があると説明しています。
危ない誘いは、「この自動化を入れるだけで月◯◯万円が当たり前」「必ず儲かる」「返金保証でノーリスク」と言い切るのに、何をしたら誰がどう儲かるかが説明できないタイプです。もう一つは、作業の中身が“規約違反ギリギリ”なのに、リスク説明が一切ないタイプです。こちらは、運よく短期で稼げても、BANや炎上で長期が崩れます。
自分が売る側になったときも同じで、数字を言うなら根拠を用意し、言い切りを避け、できないこと(例:完全放置で確実に儲かる)を約束しないほうが安全です。
事故が起きた時の対応
「事故はゼロにできない」から、型があるほど被害が小さくなるからです。IPAは最新の脅威情報をまとめており、事業や体制に照らしてリスクを洗い出して対策する重要性を強調しています。
また、アラートは“原因”ではなく“ユーザー影響に近い症状”で、行動できる(actionable)ものにするのがよい、という考え方が示されています。
個人情報が絡む事故なら、漏えい等の報告や本人通知が必要になるケースがある、と個人情報保護委員会が整理しています。
困ったときの相談先として、IPAはインシデント初動の相談窓口も案内しています。
週1運用でも回る「事故対応の型」は次の流れです。まず自動処理を止める、次に影響範囲(誰が困るか、いつからか)を短くまとめて告知し、復旧したら同じ事故が起きないように原因と再発防止を1枚で残します。個人情報が絡む可能性があるなら、ログや証拠を消さずに保全しつつ、必要な報告・通知の要否を早めに確認します。こうした“型”があるだけで、炎上と信用低下をかなり減らせます。
表にすると、避けたい地雷と安全側の代わり道はこう整理できます。
| やりたいこと | 危ない理由 | 安全側の代わり道 |
|---|---|---|
| SNSの自動フォローで集客 | 規約で禁止されやすくBANに直結しやすい | 公式の範囲で予約投稿や分析だけに寄せる |
| 画面スクレイピングでデータ収集 | 規約違反や制限、仕様変更で突然止まる | 公式API、許可を取った提携、ユーザー入力にする |
| 大量自動生成で検索流入を狙う | スパム扱いで順位が落ちやすい | 量より品質、独自性と検証を足す |
| 個人情報をログに残す | 漏えい時の対応コストが一気に増える | 最小化、マスク、短期保管、権限を絞る |
| 定期課金の説明があいまい | 返金・苦情・行政対応につながりやすい | 最終確認画面で条件を明確化する |
まとめ
Python自動化の副業は、仕組みが回りだすほど「規約・法務・セキュリティ」が売上そのものになります。SNSやスクレイピング、自動投稿は規約で止められやすいので、公式に許可された方法を優先するとBAN耐性が上がります。個人情報は集めない・残さない・見せないが基本で、漏えい時の報告や通知が必要になるケースもあるため、最初から最小化と管理を入れるのが安全です。決済や定期購入は説明不足がトラブルの元なので、表示と解約・返金の導線を先に整えると、週1運用にも近づきます。最後に、事故は起きる前提で「止める→告知→復旧→再発防止」の型を用意しておくと、炎上と信用低下を減らせます。
収益化に必要な周辺スキル
Pythonで「自動で回る収益」を作るには、プログラムを書く力だけでは足りません。APIで外とつなぐ力、DBで状態を正しく残す力、クラウドで安定して動かす力、決済でお金の流れを作る力、監視で止まる前に気づく力がそろうと、はじめて“お金が止まりにくい仕組み”になります。
API連携
収益化プロダクトの多くが「外部サービスのAPI」を使うからです。APIは便利ですが、認証が弱いと不正利用され、呼びすぎると制限され、ネットワークが不安定だと失敗します。OAuth 2.0は「必要な範囲だけアクセスを許す」考え方を定義しており、API連携の基本になります。
たとえば「価格変動を監視して通知する」サービスを作るなら、まず“誰が呼んだか”を確かめる認証(APIキーやOAuth)を入れます。次に、同じデータを何度も取りに行かないようにキャッシュを入れて、呼びすぎ(レート制限)を避けます。さらに、失敗したときはすぐあきらめずに、少し待ってから数回だけやり直すようにします。決済系のAPIは二重請求が怖いので、同じ操作を「もう一度送っても同じ結果にする」仕組み(冪等性)がとても大事で、Stripeは冪等キーの考え方を明確に説明しています。
DB設計
収益化で一番こわい事故が「状態の管理ミス」だからです。たとえばサブスクなら「課金中か」「停止中か」「支払い失敗中か」を間違えると、請求トラブルかサービス停止につながります。DBに“今の状態”だけでなく“いつ何が起きたか”の履歴を残すと、問題が起きても説明と復旧がしやすくなります。
最低限この3つの考え方があると強いです。1つ目は「履歴を残す」。2つ目は「同じイベントを2回受け取っても壊れない」。3つ目は「同時に処理が走っても二重処理になりにくい」です。PostgreSQLでは、INSERT ... ON CONFLICT DO UPDATE のような“入れるか更新するか”の動きが整理されていて、競合時のふるまいも説明されています。
たとえばStripeのWebhookは、相手側の都合で同じイベントが再送されることがあります。だからDBには「このイベントIDはもう処理した」という記録を入れて、2回目は何もしないようにします。StripeはWebhookが未配信だった場合に最大3日間再送することを説明しています。
表でまとめると、こんな持ち方が分かりやすいです。
| 何を入れる箱 | 入れるもの(例) | それが必要な理由 |
|---|---|---|
| 顧客 | 顧客ID、連絡先、プラン | 誰に何を提供しているかを間違えないため |
| 課金状態 | 現在の状態、更新日時、次回請求日 | 「今動かしていいか」を判断するため |
| イベント履歴 | WebhookのイベントID、処理結果 | 二重処理を防ぎ、説明できるようにするため |
| ログ要約 | 失敗回数、最終成功日時 | 週1運用でも健康状態を見られるようにするため |
クラウド運用
収益化は「動いている時間が価値」だからです。動かす場所が不安定だと、売上も信用も落ちます。さらに怖いのは、バグや設定ミスでコストが知らないうちに増えることです。
最初の現実解は「小さく動かして、上限を決める」です。サーバレス(例:Lambda)なら、使った分だけ課金になりやすく、まず小さく始めやすいです。AWSはLambdaの料金が“リクエスト数”と“実行時間”で決まることを示しています。
一方で、ログを出しすぎると監視費用が増えます。CloudWatchの料金ページや、コストを下げる考え方の公式資料でも「ログなどの利用量がコストになる」ことが前提になっています。
だから、最初からAWS Budgetsのような仕組みで「今月はいくらまで」を決め、近づいたら知らせるのが安全です。
別の選択肢としてCloud Runのようなサービスもあり、料金や無料枠の考え方が公開されています。
コスト上限の決め方を、ざっくり表にするとこうです。
| どこが増えやすいか | 起きがちな原因 | 先に入れる安全策 |
|---|---|---|
| 実行回数 | 失敗して再実行が増える | 再試行回数に上限、異常回数で停止 |
| ログ量 | デバッグログを出し続ける | 重要ログだけ、保存期間を短く |
| 外部API | 同じものを何度も取り直す | キャッシュ、差分取得、レート制限 |
| 通知 | 成功も毎回送ってしまう | 失敗だけ即時、成功は週1まとめ |
決済導入
決済は「お金が動く場所」なので、失敗すると直接トラブルになるからです。特にサブスクは、請求、支払い回収、失敗時の再請求、解約など、考えることが増えます。Stripeは継続課金の選び方や、サブスクリプションの流れ(作成、請求、回収、更新、解約)を整理しています。
週1運用で回したいなら、まず「支払い失敗に気づく」設計が重要です。Stripeは請求書の支払いが失敗したときのイベントや、サブスクでWebhookを使う考え方を説明しています。
また、Webhookは再送が起こり得るので、さっきのDB設計とセットで「二重処理しない」を入れます。
単発販売・サブスク・請求書運用の選び分けは、たとえばこんな感じです。単発販売は「買ったら終わり」なので運用が軽く、初心者の最初の収益化に向きます。サブスクは運用が増えますが、うまく回ると安定します。請求書運用はB2Bで相性が良い反面、入金確認や締め日などの“人のルール”が増えやすいので、最初は範囲を小さくするのが安全です。
監視・通知・CI/CD
「止まったことに気づけない」と売上が静かにゼロになるからです。監視は難しそうに見えますが、最初は“最低限の通知”があれば十分です。SentryはPythonのエラー監視の導入方法を示しており、例外を集めて原因にたどり着きやすくする考え方が整理されています。
さらに、OpenTelemetryはメトリクス・ログ・トレースを集めるための枠組みとして整備されています。
週1運用にしたいなら「失敗だけ鳴る」を基本にします。たとえば毎朝のレポート生成が失敗したらSlackかメールで通知し、成功は週1でまとめて見るようにします。メール送信にも費用がかかるので、送信数が増える設計はコスト面でも注意が必要で、Amazon SESは送信料金を明示しています。
CI/CDは「直したものを安全に出す」ために効きます。GitHub Actionsはワークフローをイベントやスケジュールで動かせることが公式に説明されていて、定期処理やテスト自動化にも使えます。
ただし、決済キーなどの秘密情報はコードに書かず、Secretsとして管理するのが基本で、GitHubもSecretsの使い方を整理しています。
インフラをコードで管理する場合も、状態ファイルに秘密が入るリスクがあるので、Terraformは機密データの扱い(状態の保護)について注意点をまとめています。
まとめ
収益化に必要な周辺スキルは、全部を完璧にすることより、事故が起きにくい最小セットをそろえることが大切です。APIは認証と呼びすぎ対策と失敗時のやり直し、DBは履歴と二重処理防止、クラウドは上限つきの運用、決済は失敗イベントを拾う設計、監視は失敗だけ気づける通知と安全なデプロイ、という順で整えると、週1運用でも回りやすくなります。
Python副業 稼げないと言われる理由と、再現性を上げる改善策
Python副業が「稼げない」と言われやすいのは、技術そのものが弱いからではなく、需要の決め方・売り方・続く設計・安全性が弱いまま進めてしまう人が多いからです。
再現性を上げるコツは、B2Bの困りごと(毎月くり返す仕事)に寄せて、自動化し、運用を最小にすることです。取引や支払いがオンラインに寄っている今は、この形が作りやすいです。
技術より「誰の課題か」が弱い
作る前に「誰が困っているか」を決めないと、完成しても欲しい人に刺さりません。実際に副業をしたい人は増えていて、追加で仕事をしたい人も多いのに、稼げる人と稼げない人が分かれます。これは「作れる」だけでは足りないサインです。
また、企業のDXでは「データをちゃんと使えるほど成果が出やすい」という傾向が示されています。つまり、データ整理・集計・可視化のような地味な困りごとは需要が出やすいです。
いきなり「自動収益」を狙うより、「ネットショップ担当者の毎朝20分の集計を0分にする」など、対象と時間を決めます。CSVを入れたら売上・利益・前年差だけが1枚で出る、のように“助かる瞬間”が分かる形にすると、買う理由が強くなります。
集客・販売導線がない
ネットで買う土台は大きいのに、そこに乗せないと売上は生まれません。日本の電子商取引市場は伸びており、BtoCもBtoBも規模が大きく、オンラインで申し込み・購入する行動が当たり前になっています。
支払い面でもキャッシュレスが広がっていて、「説明して、すぐ払える」流れを作りやすい状況です。
ツールができたら同時に「買うまでの道」を作ります。1枚の説明ページで、誰の何分が減るか、デモ画像、料金、申し込みボタンまで置きます。さらに無料版(回数制限や機能制限)を用意して、「使って良かった」を作ってから有料にします。ここまでやって初めて、作ったものが“売れるもの”に近づきます。
単発で終わる設計
単発納品だけだと毎月ゼロから売ることになり、疲れて止まりやすいです。一方で企業の取引はどんどん電子化しており、BtoBの取引規模も大きいので、「毎月払って使う」形に乗せやすい土台があります。
また、DXの事例でも、必要最小限の取り組みから進める会社の例が示されていて、継続的に改善する考え方が現実的だと分かります。
最初は単発の「集計スクリプト」を納品してもOKです。ただし次の一手で、毎週・毎月の“くり返し”を商品にします。たとえば「毎週レポート自動生成+配信+監視」を月額にして、軽い保守(仕様変更の対応、止まった時の復旧)も含めます。こうすると収益が積み上がりやすくなり、月5万・月10万の再現性が上がります。
グレー領域に寄って詰む
「早く稼げそう」に見える自動化ほど、規約で止められたり炎上したりしやすいです。たとえばSNSでは大量・無差別な自動フォローや自動操作が禁止されていると明記されています。
スクレイピングも、無断の情報収集が規約違反だとして制限される例があります。
集客で検索や動画に寄せる場合も、大量生成で順位操作を狙う行為がスパムとして扱われる方針が示されています。
広告収益では、無効なトラフィック(自動・誘導・不正など)が問題になり、収益制限やアカウント閉鎖につながり得ると説明されています。
さらに「簡単に稼げる」をうたう副業勧誘について、消費者庁が注意喚起を出していて、うまい話ほど危ないことが分かります。
SNSの自動フォローで集客しようとしたり、禁止されやすい形のスクレイピングに依存したり、広告クリックを増やすような仕組みに寄せると、ある日突然止まります。安全策としては、公式APIや公開データ、許可を取った提携、ユーザー自身の入力データに寄せて、「止められにくい土台」で商品を作る方が長く続きます。
伸ばすコツ:B2B課題×自動化×運用最小化に寄せる
B2Bは「毎月くり返す作業」が多く、効果が数字で出やすいので、価値が説明しやすいです。取引の電子化が進んでいることも追い風です。
また、企業のDXではデータ利活用が成果につながりやすい傾向が示されているので、集計・レポート・監視のような自動化が刺さりやすいです。
再現性が上がりやすい形は「運用が軽い商品」に寄せることです。定期レポート自動生成、監視・通知、業務自動化パッケージは、作りやすく売りやすい代表例です。週1運用で回せるように、失敗だけ通知、成功はまとめ、問い合わせはFAQで減らす、という運用設計までセットにします。
次の表は、稼げない状態から抜けるためのチェック表です。
| つまずきポイント | よくある状態 | 改善の一手 |
|---|---|---|
| 需要が弱い | 「便利そう」だけで誰向けか不明 | 「誰の何分を減らすか」を固定する |
| 売り方がない | GitHubに置いて満足して終わる | 説明ページ・デモ・料金・申し込みを用意する |
| 単発止まり | 1回納品して終わる | 月額の保守・定期レポート・監視に伸ばす |
| グレー依存 | 自動フォロー、無断スクレイピング等 | 公式API・公開データ・許可・入力データへ寄せる |
| 運用が重い | 問い合わせ地獄で続かない | 失敗だけ通知、FAQ、ログ整備で週1運用にする |
まとめ
Python副業が稼げないと言われる主な理由は、「誰の課題かが弱い」「売り方がない」「単発で終わる」「グレーに寄って止まる」の4つです。
再現性を上げるなら、B2Bのくり返し作業に寄せて、自動化し、運用を最小化する形にします。安全で続く仕組みにすると、少ない時間でも積み上がりやすくなります。
まとめ:Pythonで自動収益を総括
Pythonで「自動収益」を狙うとき、目標を“完全な不労所得”に置くと失敗しやすいです。
現実的には、最初にしっかり作り込み、あとは週1チェックで回る「手離れの良い仕組み」を作るのがプロの定石です。
収益は、次の3点がそろって初めて安定します。
① 価値提供(誰の何分を減らすか)
② 課金導線(払いやすい導線と条件の明確化)
③ 運用自動化(定期実行→処理→通知+ログ/監視)
Pythonが強いのは、データ収集・整形・レポート生成・配信・監視通知・請求補助など、“運用”の省力化です。
一方で、集客や信用づくりをゼロにする魔法ではありません。
再現性を上げるなら、規約違反になりやすい自動フォローや無断スクレイピング、広告クリック誘導などのグレー領域を避け、
公式API・公開データ・許可取得・ユーザー入力の範囲で設計します。
収益モデルは、次が堅実です。
マイクロSaaS(定期課金)/定期レポート販売/テンプレ・ツール販売/API従量課金
土日運用なら、7〜14日でMVPを作り、LPで先に需要を確認し、売れた型だけを横展開します。
最後に、冪等性・リトライ・コスト上限・FAQで“止まらない運用”を先に仕込むほど、収益は積み上がります。
特に重要なポイント
- 「不労」ではなく「手離れ(週1運用)」を目標にする
- 収益の3要素:価値提供 × 課金導線 × 運用自動化
- 価値は「誰の何分を減らすか」を数字で固定する
- 自動化の最小形:定期実行 → 処理 → 通知(+ログ/監視)
- 事故を防ぐ土台:冪等性・リトライ・ステージング保存・成功日時の記録
- 危険な近道を避ける:SNS自動操作/無断スクレイピング/無効トラフィックはBANリスク
- 強いモデル:マイクロSaaS/定期レポート/テンプレ販売/API従量課金
- MVPは7〜14日で「入力1つ・出力1つ・1回で役立つ」に絞る
- コスト暴走対策:予算アラート、ログ保存期間の制限、成功通知は週1まとめ
- サポート削減:オンボーディング1枚+FAQ3つ+短い手順(画像/動画)で問い合わせを減らす